Generate an adapter for an LLM?
Asked on 2024-07-31
1 search

To generate an adapter for a large language model (LLM) on Apple platforms, you can follow the steps outlined in the sessions from WWDC. Here are the key points and relevant sessions:
-
Understanding Adapters:
- Adapters are small modules embedded into an existing network and trained with its knowledge for another task. They allow a single base model to be shared across multiple adapters, making it efficient to extend the functionality of a large pre-trained model without adjusting its weights.
- For more details, refer to the session Deploy machine learning and AI models on-device with Core ML at the chapter "Multifunction models".
-
Implementing Adapters with Core ML:
- You can use Core ML's new multifunction models to capture multiple adapters in a single model. Each adapter will be defined as a separate function, and the weights for the base model are shared as much as possible.
- For a detailed walkthrough, see the session Bring your machine learning and AI models to Apple silicon at the chapter "Multifunction model".
-
Using Metal for Adapters:
- You can add adapters to your model using Metal Performance Shaders (MPS) graph callables. Each adapter is a separate MPS graph that can be called from the main graph.
- For implementation details, refer to the session Accelerate machine learning with Metal at the chapter "Transformer support".
-
Example Code:
- Define the shape and type of the output the call to your adapter will produce.
- Use the call method on your main MPS graph object to add the call to your adapter.
- Create the MPS graph for each adapter and compile the graphs into graph executables.
- Map the adapter names to the actual graph executables in the main graph using a graph compilation descriptor.
By following these steps, you can efficiently generate and integrate adapters for your LLM on Apple platforms, leveraging the power of Apple Silicon and Core ML.
Relevant Sessions:
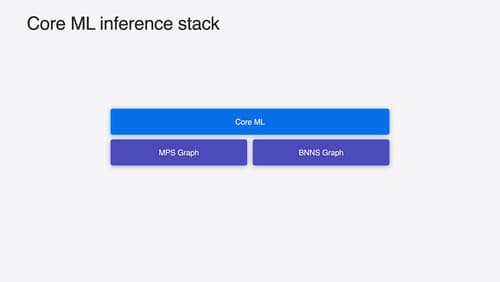
Deploy machine learning and AI models on-device with Core ML
Learn new ways to optimize speed and memory performance when you convert and run machine learning and AI models through Core ML. We’ll cover new options for model representations, performance insights, execution, and model stitching which can be used together to create compelling and private on-device experiences.
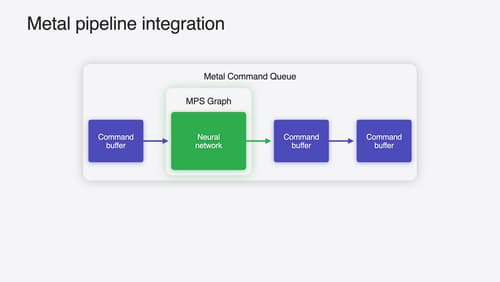
Accelerate machine learning with Metal
Learn how to accelerate your machine learning transformer models with new features in Metal Performance Shaders Graph. We’ll also cover how to improve your model’s compute bandwidth and quality, and visualize it in the all new MPSGraph viewer.
Explore machine learning on Apple platforms
Get started with an overview of machine learning frameworks on Apple platforms. Whether you’re implementing your first ML model, or an ML expert, we’ll offer guidance to help you select the right framework for your app’s needs.