How to improve RAG with local LLM?
Asked on 2024-07-31
1 search

To improve Retrieval-Augmented Generation (RAG) with a local Large Language Model (LLM) on Apple silicon, you can leverage several techniques and tools discussed in various WWDC sessions:
-
Model Compression:
- Palletization and Quantization: These techniques can significantly reduce the model size while maintaining accuracy. For instance, iOS 18 introduces per-grouped channel palletization, which increases granularity by having multiple lookup tables, and extends support from 8-bit to 4-bit quantization, optimized for GPUs on Macs. Combining sparsity with other compression modes can also help in reducing the model size further (Bring your machine learning and AI models to Apple silicon).
- Calibration-based Workflow: Using calibration data for post-training compression can improve the model's performance and reduce noise in the output (Bring your machine learning and AI models to Apple silicon).
-
Transformer Model Optimization:
- Improved Compute Performance and Memory Bandwidth Savings: New features in MPS and MPS Graph can enhance the performance of transformer models, which are commonly used in language models for tasks like text generation (Accelerate machine learning with Metal).
- Stateful Models: Managing key-value caches using Core ML states can reduce overhead and improve efficiency, which is particularly useful for language models that generate text based on previous context (Deploy machine learning and AI models on-device with Core ML).
-
Fine-Tuning and Adapters:
- Fine-Tuning: Running different training passes to specialize the model for specific tasks can make it more efficient for those tasks (Platforms State of the Union).
- Adapters: Using adapters, which are small collections of model weights, can make the model more efficient by allowing it to be fine-tuned for specific tasks without retraining the entire model (Platforms State of the Union).
By applying these techniques, you can improve the performance and efficiency of RAG with a local LLM on Apple silicon. For more detailed information, you can refer to the specific sessions mentioned above.
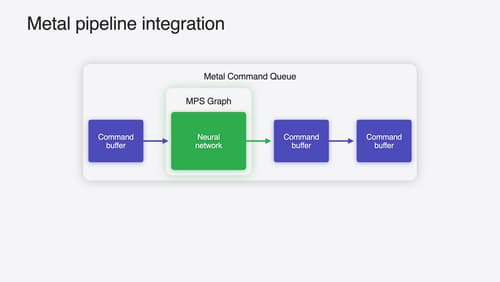
Accelerate machine learning with Metal
Learn how to accelerate your machine learning transformer models with new features in Metal Performance Shaders Graph. We’ll also cover how to improve your model’s compute bandwidth and quality, and visualize it in the all new MPSGraph viewer.
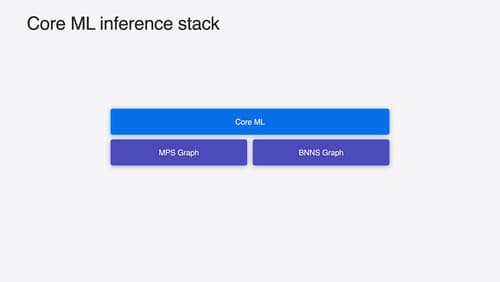
Deploy machine learning and AI models on-device with Core ML
Learn new ways to optimize speed and memory performance when you convert and run machine learning and AI models through Core ML. We’ll cover new options for model representations, performance insights, execution, and model stitching which can be used together to create compelling and private on-device experiences.
Bring your machine learning and AI models to Apple silicon
Learn how to optimize your machine learning and AI models to leverage the power of Apple silicon. Review model conversion workflows to prepare your models for on-device deployment. Understand model compression techniques that are compatible with Apple silicon, and at what stages in your model deployment workflow you can apply them. We’ll also explore the tradeoffs between storage size, latency, power usage and accuracy.