What is mlx
Asked on 2024-08-01
2 searches

MLX is a new machine learning framework designed and optimized for Apple silicon. It supports features such as a NumPy-like API, just-in-time compilation, distributed training, and unified memory. The framework offers bindings for Python, Swift, C, and C++, making it versatile for various development environments. MLX is built on top of a unified memory model, which allows for efficient operations across CPU and GPU. It is designed to facilitate researchers in exploring new ideas on Apple silicon.
For more details, you can refer to the session Train your machine learning and AI models on Apple GPUs and Explore machine learning on Apple platforms.
Relevant Sessions
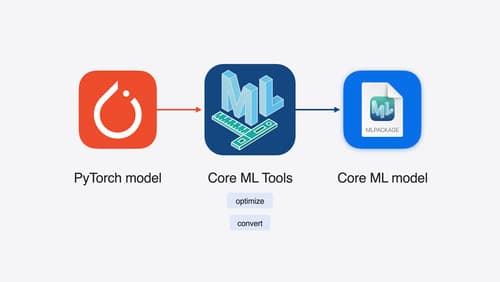
Bring your machine learning and AI models to Apple silicon
Learn how to optimize your machine learning and AI models to leverage the power of Apple silicon. Review model conversion workflows to prepare your models for on-device deployment. Understand model compression techniques that are compatible with Apple silicon, and at what stages in your model deployment workflow you can apply them. We’ll also explore the tradeoffs between storage size, latency, power usage and accuracy.

Platforms State of the Union
Discover the newest advancements on Apple platforms.
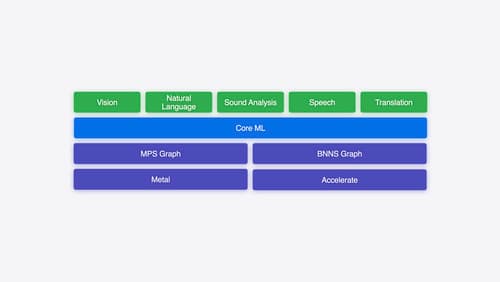
Explore machine learning on Apple platforms
Get started with an overview of machine learning frameworks on Apple platforms. Whether you’re implementing your first ML model, or an ML expert, we’ll offer guidance to help you select the right framework for your app’s needs.