how do i train an LLM to understand my collection of digitized historical documents?
Asked on 2024-08-02
1 search

To train a Large Language Model (LLM) to understand your collection of digitized historical documents, you can follow a process similar to the one described in the WWDC sessions. Here are the steps you can take:
-
Select a Base Model: Choose a pre-trained language model that you can fine-tune for your specific use case. For example, you can use models from the Hugging Face repository, such as OpenLlama.
-
Prepare Your Data: Organize your digitized historical documents into a dataset. Ensure that the data is in a format that the model can consume, such as plain text files.
-
Tokenization: Use a tokenizer that corresponds to your chosen base model. Tokenization is the process of converting text into a format that the model can understand.
-
Fine-Tuning: Fine-tune the base model using your dataset. This involves setting training parameters such as batch size and the number of training epochs. You can use libraries like PyTorch and the Transformers library for this purpose.
-
Training: Train the model on your dataset. This process will adjust the model's weights based on your specific data, allowing it to better understand and generate text related to your historical documents.
-
Evaluation: After training, evaluate the model's performance to ensure it meets your expectations. You can use various metrics and test it with sample inputs to see how well it understands and generates relevant text.
Here are some relevant sessions from WWDC that can help you with this process:
- Train your machine learning and AI models on Apple GPUs: This session covers how to take a language model, customize it, fine-tune it to your use case, and run it on your device.
- What’s new in Create ML: This session discusses enhancements to the CreateML app, which can be useful for customizing machine learning models with your training data.
- Explore machine learning on Apple platforms: This session provides an overview of Apple's ML-powered APIs and how you can use CreateML to customize models for your specific use case.
By following these steps and utilizing the resources provided in the WWDC sessions, you can effectively train an LLM to understand and work with your collection of digitized historical documents.
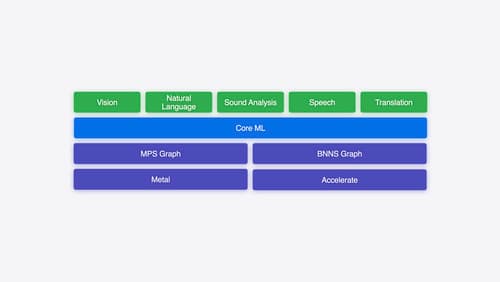
Explore machine learning on Apple platforms
Get started with an overview of machine learning frameworks on Apple platforms. Whether you’re implementing your first ML model, or an ML expert, we’ll offer guidance to help you select the right framework for your app’s needs.
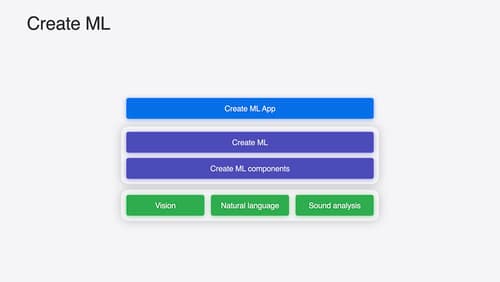
What’s new in Create ML
Explore updates to Create ML, including interactive data source previews and a new template for building object tracking models for visionOS apps. We’ll also cover important framework improvements, including new time-series forecasting and classification APIs.
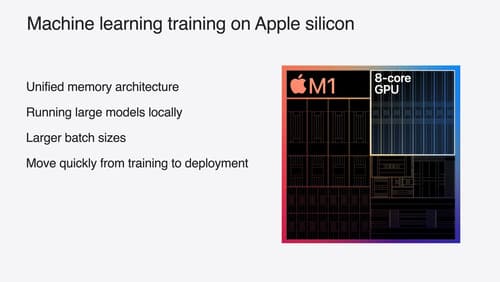
Train your machine learning and AI models on Apple GPUs
Learn how to train your models on Apple Silicon with Metal for PyTorch, JAX and TensorFlow. Take advantage of new attention operations and quantization support for improved transformer model performance on your devices.