Can I run llm in my phone?
Asked on 2024-08-02
1 search

Yes, you can run large language models (LLMs) on your phone. Apple provides tools and frameworks to help you import and run AI models, including large language models, on various Apple devices such as iPhones.
You can start with any PyTorch model and convert it into the Core ML format using Core ML tools. These tools offer various optimization techniques, such as quantization and efficient key-value caching in LLMs, to ensure the model runs efficiently on Apple hardware. Core ML optimizes hardware-accelerated execution across the CPU, GPU, and neural engine, making it suitable for running AI models on iOS devices.
For more details, you can refer to the Platforms State of the Union session from WWDC 2024.
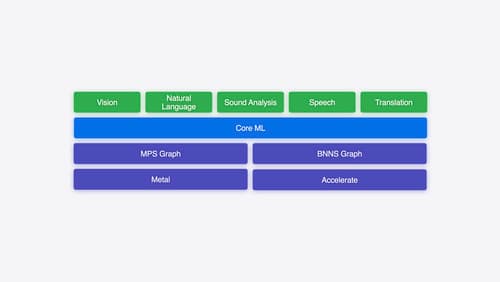
Explore machine learning on Apple platforms
Get started with an overview of machine learning frameworks on Apple platforms. Whether you’re implementing your first ML model, or an ML expert, we’ll offer guidance to help you select the right framework for your app’s needs.
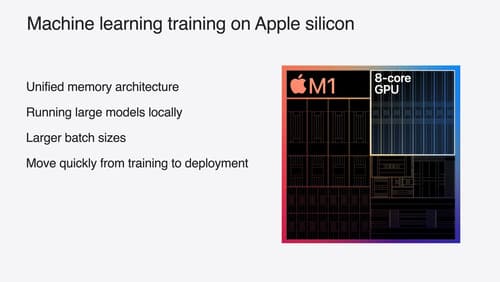
Train your machine learning and AI models on Apple GPUs
Learn how to train your models on Apple Silicon with Metal for PyTorch, JAX and TensorFlow. Take advantage of new attention operations and quantization support for improved transformer model performance on your devices.

Platforms State of the Union
Discover the newest advancements on Apple platforms.