When was the Compression framework introduced?
Asked on 2024-08-05
1 search

The Compression framework was not explicitly introduced in the provided context. However, the context does discuss various compression techniques and workflows in the session titled "Bring your machine learning and AI models to Apple silicon" from WWDC 2024.
For more detailed information on model compression techniques and workflows, you can refer to the chapter on "Model compression" in the session Bring your machine learning and AI models to Apple silicon.
Train your machine learning and AI models on Apple GPUs
Learn how to train your models on Apple Silicon with Metal for PyTorch, JAX and TensorFlow. Take advantage of new attention operations and quantization support for improved transformer model performance on your devices.
Deploy machine learning and AI models on-device with Core ML
Learn new ways to optimize speed and memory performance when you convert and run machine learning and AI models through Core ML. We’ll cover new options for model representations, performance insights, execution, and model stitching which can be used together to create compelling and private on-device experiences.
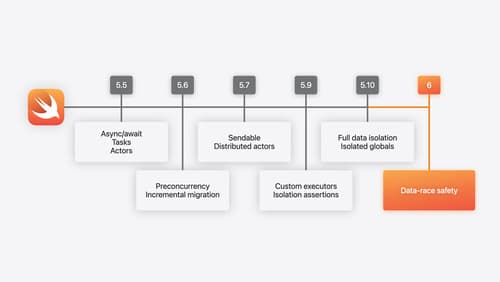
What’s new in Swift
Join us for an update on Swift. We’ll briefly go through a history of Swift over the past decade, and show you how the community has grown through workgroups, expanded the package ecosystem, and increased platform support. We’ll introduce you to a new language mode that achieves data-race safety by default, and a language subset that lets you run Swift on highly constrained systems. We’ll also explore some language updates including noncopyable types, typed throws, and improved C++ interoperability.