Combine
Asked on 2024-08-09
14 searches

The content from the WWDC sessions highlights several advancements in machine learning and AI models on Apple platforms. Here are some key points:
-
Multifunction Models: Apple introduced support for multifunction models in Core ML, allowing multiple functions to be merged into a single model. This is particularly useful for models that share a feature extractor but have different outputs, such as a classifier and a regressor. This feature is discussed in the session Bring your machine learning and AI models to Apple silicon.
-
Real-time ML Inference on CPU: The session on real-time ML inference discusses optimizations like layer fusion and memory sharing to enhance performance. These optimizations are automatically applied, providing significant speed improvements without requiring code changes. This is covered in the session Support real-time ML inference on the CPU.
-
Deploying Models On-Device: Core ML now supports deploying models with multiple functions, allowing for more efficient use of resources by sharing a single base model across different adapters. This is explained in the session Deploy machine learning and AI models on-device with Core ML.
-
Accelerating ML with Metal: The session on Metal discusses improvements in handling transformer models, including the use of KV cache and new operations to enhance compute performance. This is detailed in the session Accelerate machine learning with Metal.
These sessions collectively provide insights into how Apple is enhancing the performance and efficiency of machine learning models on its platforms, making it easier for developers to integrate and optimize AI functionalities in their applications.
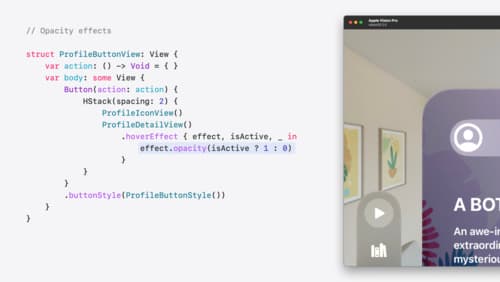
Create custom hover effects in visionOS
Learn how to develop custom hover effects that update views when people look at them. Find out how to build an expanding button effect that combines opacity, scale, and clip effects. Discover best practices for creating effects that are comfortable and respect people’s accessibility needs.
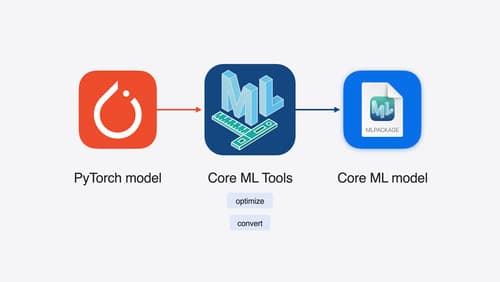
Bring your machine learning and AI models to Apple silicon
Learn how to optimize your machine learning and AI models to leverage the power of Apple silicon. Review model conversion workflows to prepare your models for on-device deployment. Understand model compression techniques that are compatible with Apple silicon, and at what stages in your model deployment workflow you can apply them. We’ll also explore the tradeoffs between storage size, latency, power usage and accuracy.
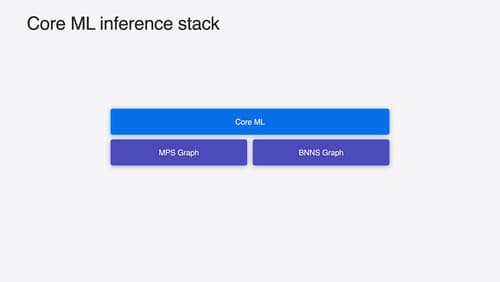
Deploy machine learning and AI models on-device with Core ML
Learn new ways to optimize speed and memory performance when you convert and run machine learning and AI models through Core ML. We’ll cover new options for model representations, performance insights, execution, and model stitching which can be used together to create compelling and private on-device experiences.