Transformer optimization에 대해 자세히 설명해줘 한글로
Asked on 2024-08-12
1 search

Transformer optimization is a key focus in several sessions at WWDC 2024. Transformers are widely used in language models for tasks such as translation, prediction, and text generation. The optimization efforts are aimed at improving compute performance, memory bandwidth savings, and overall quality of transformer models.
-
Compute Performance: Transformer models consist of layers of transformer blocks, including multi-head attention, normalization, and feedforward blocks. The multi-head attention block is particularly compute-intensive, involving large multi-dimensional matrix multiplications. Optimizations include fusing operations into a single kernel call to reduce overhead and improve performance on Apple GPUs.
-
Memory Bandwidth Savings: The unified memory architecture on Apple devices allows tensors to exist in main memory, accessible by both CPU and GPU, eliminating the need for memory copying and improving efficiency.
-
Quality Improvements: Techniques such as stateful key-value caching and fused representations for scaled dot product attention (SDPA) are used to enhance the efficiency of attention calculations, particularly on Apple silicon GPUs.
For more detailed information on transformer optimizations, you can refer to the session Accelerate machine learning with Metal (02:07) and Bring your machine learning and AI models to Apple silicon (17:08).
Train your machine learning and AI models on Apple GPUs
Learn how to train your models on Apple Silicon with Metal for PyTorch, JAX and TensorFlow. Take advantage of new attention operations and quantization support for improved transformer model performance on your devices.
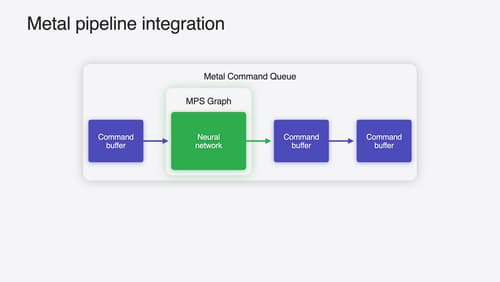
Accelerate machine learning with Metal
Learn how to accelerate your machine learning transformer models with new features in Metal Performance Shaders Graph. We’ll also cover how to improve your model’s compute bandwidth and quality, and visualize it in the all new MPSGraph viewer.

Platforms State of the Union
Discover the newest advancements on Apple platforms.