what is mistral-on-device?
Asked on 2024-07-30
1 search

Mistral-on-device refers to the capability of running the Mistral model, a type of large language model, directly on Apple devices using Core ML. This allows developers to leverage the power of Mistral for various applications without needing to rely on cloud-based services, thus ensuring better performance and privacy.
The process involves converting the Mistral model into the Core ML format and optimizing it for execution on Apple hardware, such as the CPU, GPU, and neural engine. This includes techniques like quantization and efficient key-value caching to enhance performance and reduce memory usage.
For more details, you can refer to the session Explore machine learning on Apple platforms and Platforms State of the Union.
Relevant Sessions
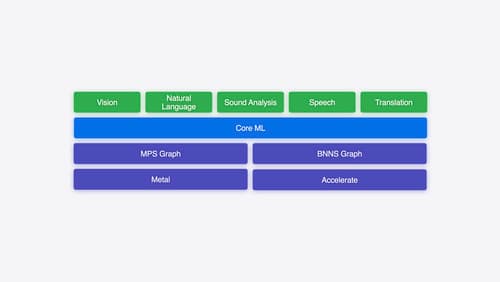
Explore machine learning on Apple platforms
Get started with an overview of machine learning frameworks on Apple platforms. Whether you’re implementing your first ML model, or an ML expert, we’ll offer guidance to help you select the right framework for your app’s needs.

Platforms State of the Union
Discover the newest advancements on Apple platforms.
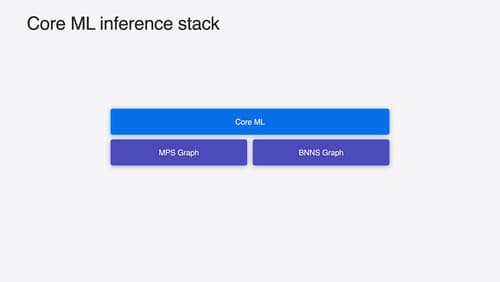
Deploy machine learning and AI models on-device with Core ML
Learn new ways to optimize speed and memory performance when you convert and run machine learning and AI models through Core ML. We’ll cover new options for model representations, performance insights, execution, and model stitching which can be used together to create compelling and private on-device experiences.