how do I reduce the size of an ml model to run on it on my mac
Asked on 2024-08-12
1 search

To reduce the size of a machine learning model for running on your Mac, you can use several model compression techniques available in Apple's Core ML tools. Here are some steps and techniques you can consider:
-
Model Conversion and Optimization: Convert your model into the Core ML format using Core ML tools. This conversion is optimized for execution on Apple silicon, leveraging the unified memory, CPU, GPU, and neural engine for efficient compute.
-
Quantization: Use quantization techniques to reduce the model size. For example, you can apply 4-bit quantization, which is especially optimized for GPUs on Macs. This can significantly reduce the model size while maintaining performance. You can use the
CT optimizemodule to specify the compression configuration, such as using the linear quantizer with a specific data type and granularity. -
Compression Techniques: Explore other compression techniques like sparsity, which can be combined with quantization to further reduce model size. These techniques are designed to work well with Apple's neural engine.
-
Testing and Tuning: After applying compression techniques, it's important to test and tune the model to ensure that the output quality remains acceptable. Quantization, for instance, can affect output quality, so additional testing is recommended.
For more detailed guidance, you can refer to the session Bring your machine learning and AI models to Apple silicon (02:47) which covers model compression techniques in depth.
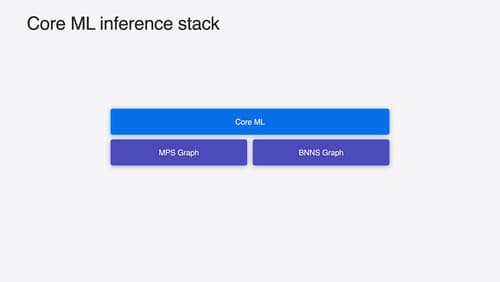
Deploy machine learning and AI models on-device with Core ML
Learn new ways to optimize speed and memory performance when you convert and run machine learning and AI models through Core ML. We’ll cover new options for model representations, performance insights, execution, and model stitching which can be used together to create compelling and private on-device experiences.
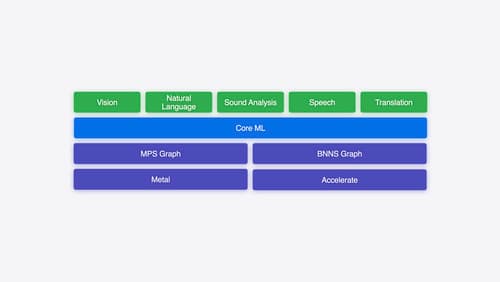
Explore machine learning on Apple platforms
Get started with an overview of machine learning frameworks on Apple platforms. Whether you’re implementing your first ML model, or an ML expert, we’ll offer guidance to help you select the right framework for your app’s needs.
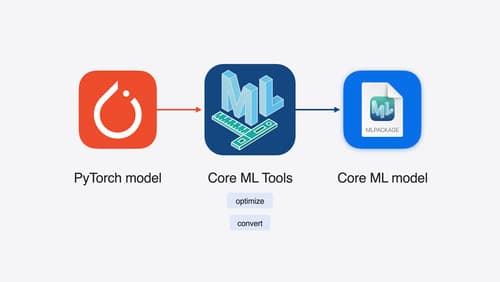
Bring your machine learning and AI models to Apple silicon
Learn how to optimize your machine learning and AI models to leverage the power of Apple silicon. Review model conversion workflows to prepare your models for on-device deployment. Understand model compression techniques that are compatible with Apple silicon, and at what stages in your model deployment workflow you can apply them. We’ll also explore the tradeoffs between storage size, latency, power usage and accuracy.