core ml channel 과 block 설명해줘
Asked on 2024-08-20
1 search

Core ML is a framework by Apple that allows developers to deploy machine learning and AI models on Apple devices. It provides tools to efficiently run models on-device, leveraging the CPU, GPU, and neural engine to maximize hardware utilization. Core ML supports features like ML tensor for simplifying model integration, multifunction models for deploying models with multiple functionalities, and performance tools for profiling and debugging models.
In the context of Core ML, a "channel" is not directly related. However, in the context of broadcasting updates to Live Activities, a channel is a mechanism to manage and send broadcast push notifications. You can create a channel for your app using the push notifications console or directly through the app server in production. This channel is used to subscribe to updates and send notifications to live activities.
For more detailed information on Core ML and its features, you can refer to the session Deploy machine learning and AI models on-device with Core ML.
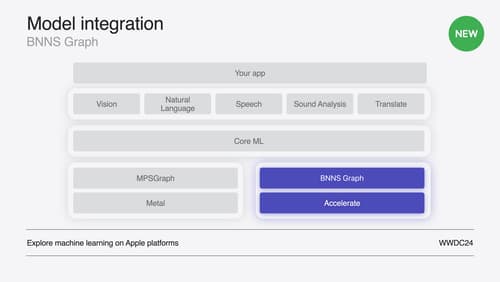
Support real-time ML inference on the CPU
Discover how you can use BNNSGraph to accelerate the execution of your machine learning model on the CPU. We will show you how to use BNNSGraph to compile and execute a machine learning model on the CPU and share how it provides real-time guarantees such as no runtime memory allocation and single-threaded running for audio or signal processing models.
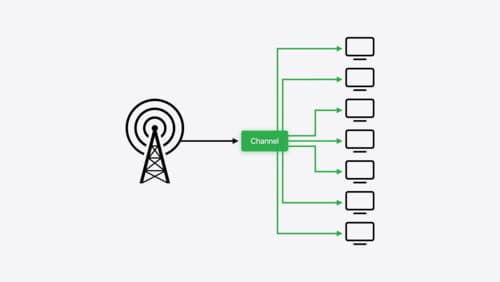
Broadcast updates to your Live Activities
With broadcast push notifications, your app can send updates to thousands of Live Activities with a single request. We’ll discover how broadcast push notifications work between an app, a server, and the Apple Push Notification service, then we’ll walk through best practices for this capability and how to implement it.
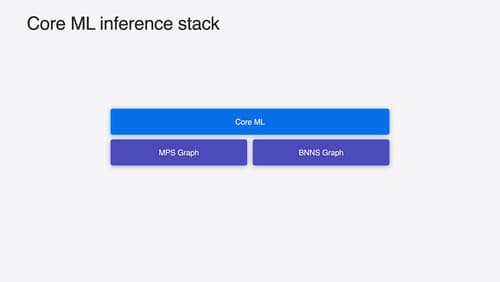
Deploy machine learning and AI models on-device with Core ML
Learn new ways to optimize speed and memory performance when you convert and run machine learning and AI models through Core ML. We’ll cover new options for model representations, performance insights, execution, and model stitching which can be used together to create compelling and private on-device experiences.