what is mergeable
Asked on 2024-08-22
1 search

In the context of Apple's WWDC sessions, "mergeable" refers to the ability to combine multiple machine learning models into a single multifunction model using Core ML tools. This feature allows for the deduplication of shared weights by calculating hash values, enabling a single model to perform multiple tasks with a shared feature extractor. This is particularly useful for models that have different functions, such as a classifier and a regressor, which can be merged to operate together efficiently.
For more details, you can refer to the session Bring your machine learning and AI models to Apple silicon (26:24).

Port advanced games to Apple platforms
Discover how simple it can be to reach players on Apple platforms worldwide. We’ll show you how to evaluate your Windows executable on Apple silicon, start your game port with code samples, convert your shader code to Metal, and bring your game to Mac, iPhone, and iPad. Explore enhanced Metal tools that understand HLSL shaders to validate, debug, and profile your ported shaders on Metal.

Build a spatial drawing app with RealityKit
Harness the power of RealityKit through the process of building a spatial drawing app. As you create an eye-catching spatial experience that integrates RealityKit with ARKit and SwiftUI, you’ll explore how resources work in RealityKit and how to use features like low-level mesh and texture APIs to achieve fast updates of the users’ brush strokes.
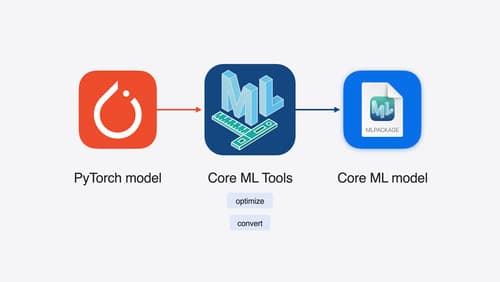
Bring your machine learning and AI models to Apple silicon
Learn how to optimize your machine learning and AI models to leverage the power of Apple silicon. Review model conversion workflows to prepare your models for on-device deployment. Understand model compression techniques that are compatible with Apple silicon, and at what stages in your model deployment workflow you can apply them. We’ll also explore the tradeoffs between storage size, latency, power usage and accuracy.