starving
Asked on 2024-08-31
1 search

It seems like you're interested in the content presented by Apple at WWDC, specifically related to machine learning and AI models. At WWDC 2024, several sessions focused on optimizing and deploying machine learning models on Apple devices. Here are some highlights:
-
Model Compression Techniques: In the session "Bring your machine learning and AI models to Apple silicon," various model compression techniques were discussed, such as palletization and quantization. These techniques help reduce model size, making it feasible to run large models on devices like iPhones and iPads. For example, eight-bit palletization can significantly reduce model size, allowing for efficient deployment on mobile devices.
-
Training on Apple GPUs: The session "Train your machine learning and AI models on Apple GPUs" covered how to customize and fine-tune language models using frameworks like PyTorch. The session also introduced the ExecuTorch framework for deploying PyTorch models across various devices.
-
On-Device Deployment with Core ML: In "Deploy machine learning and AI models on-device with Core ML," methods for deploying models on Apple devices were explored, including the use of Core ML and ML tensor optimizations for efficient inference.
-
Accelerating Machine Learning with Metal: The session "Accelerate machine learning with Metal" discussed techniques for improving compute performance and reducing memory bandwidth bottlenecks, such as using quantized formats for model weights.
If you have specific questions about these sessions or need timestamps for particular topics, feel free to ask!
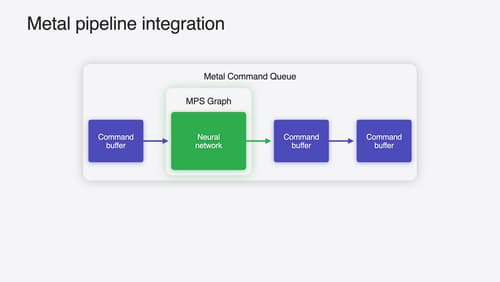
Accelerate machine learning with Metal
Learn how to accelerate your machine learning transformer models with new features in Metal Performance Shaders Graph. We’ll also cover how to improve your model’s compute bandwidth and quality, and visualize it in the all new MPSGraph viewer.
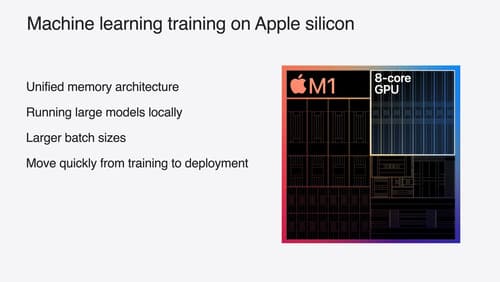
Train your machine learning and AI models on Apple GPUs
Learn how to train your models on Apple Silicon with Metal for PyTorch, JAX and TensorFlow. Take advantage of new attention operations and quantization support for improved transformer model performance on your devices.
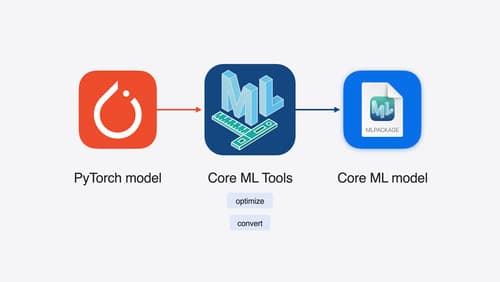
Bring your machine learning and AI models to Apple silicon
Learn how to optimize your machine learning and AI models to leverage the power of Apple silicon. Review model conversion workflows to prepare your models for on-device deployment. Understand model compression techniques that are compatible with Apple silicon, and at what stages in your model deployment workflow you can apply them. We’ll also explore the tradeoffs between storage size, latency, power usage and accuracy.