How can I use Mistral on-device?
Asked on 2024-07-16
111 searches

To use Mistral on-device, you can follow these steps as outlined in the WWDC sessions:
-
Model Training and Preparation:
- Start by defining the model architecture and training the model using libraries such as PyTorch or TensorFlow. You can leverage Apple silicon and the unified memory architecture on Mac for high-performance model training.
- Convert the trained model into the Core ML format for deployment. This involves optimizing the model representation and parameters to achieve great performance while maintaining accuracy.
-
Model Conversion and Optimization:
- Use Core ML tools to convert your model into the Core ML format. Core ML tools offer various optimization techniques, such as quantization and efficient key-value caching, to enhance model performance.
- For example, you can convert the Mistral 7B model to a Core ML model using post-training per-block quantization and other optimization techniques.
-
Integration and Execution:
- Integrate the prepared model with Apple frameworks to load and execute it within your app. Core ML optimizes hardware-accelerated execution across the CPU, GPU, and neural engine.
- Utilize Core ML's new features, such as stateful models and multifunction models, to improve inference efficiency and deployment.
For a detailed walkthrough, you can refer to the following sessions:
- Explore machine learning on Apple platforms (07:32)
- Deploy machine learning and AI models on-device with Core ML (00:07)
- Bring your machine learning and AI models to Apple silicon (19:51)
These sessions provide comprehensive guidance on preparing, optimizing, and deploying machine learning models, including Mistral, on Apple devices.

Platforms State of the Union
Discover the newest advancements on Apple platforms.
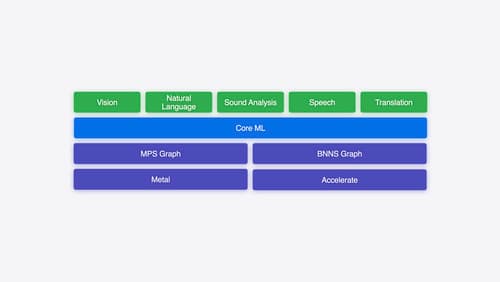
Explore machine learning on Apple platforms
Get started with an overview of machine learning frameworks on Apple platforms. Whether you’re implementing your first ML model, or an ML expert, we’ll offer guidance to help you select the right framework for your app’s needs.
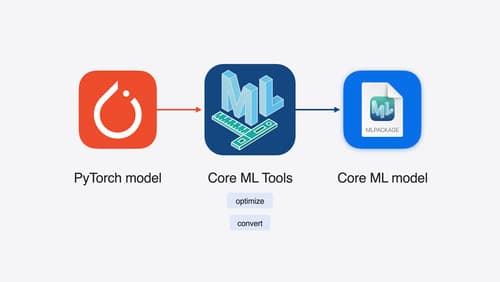
Bring your machine learning and AI models to Apple silicon
Learn how to optimize your machine learning and AI models to leverage the power of Apple silicon. Review model conversion workflows to prepare your models for on-device deployment. Understand model compression techniques that are compatible with Apple silicon, and at what stages in your model deployment workflow you can apply them. We’ll also explore the tradeoffs between storage size, latency, power usage and accuracy.