lapack
Asked on 2024-09-28
1 search

It seems like you're interested in LAPACK, which is a software library for numerical linear algebra. While LAPACK itself wasn't specifically mentioned in the provided context from WWDC, Apple has been focusing on enhancing machine learning capabilities on their platforms, particularly with Apple Silicon and Metal.
For example, the session titled "Accelerate machine learning with Metal" discusses improvements in memory bandwidth and quantization techniques, which are relevant to numerical computations and optimizations that might be of interest if you're working with linear algebra in machine learning contexts.
If you're interested in how Apple is optimizing machine learning and numerical computations, you might want to check out the sessions related to machine learning frameworks and Metal:
- Accelerate machine learning with Metal (07:14)
- Train your machine learning and AI models on Apple GPUs (02:52)
These sessions cover topics like quantization, memory optimizations, and the use of Apple's Metal framework for efficient computation, which could be relevant to your interests in numerical linear algebra.
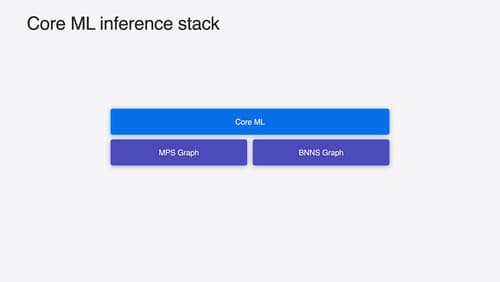
Deploy machine learning and AI models on-device with Core ML
Learn new ways to optimize speed and memory performance when you convert and run machine learning and AI models through Core ML. We’ll cover new options for model representations, performance insights, execution, and model stitching which can be used together to create compelling and private on-device experiences.
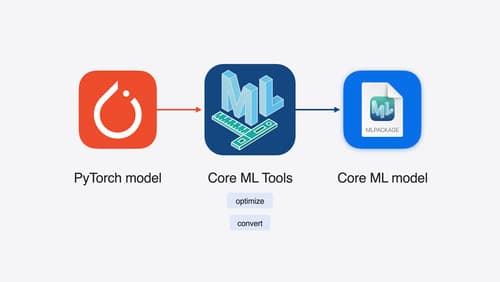
Bring your machine learning and AI models to Apple silicon
Learn how to optimize your machine learning and AI models to leverage the power of Apple silicon. Review model conversion workflows to prepare your models for on-device deployment. Understand model compression techniques that are compatible with Apple silicon, and at what stages in your model deployment workflow you can apply them. We’ll also explore the tradeoffs between storage size, latency, power usage and accuracy.
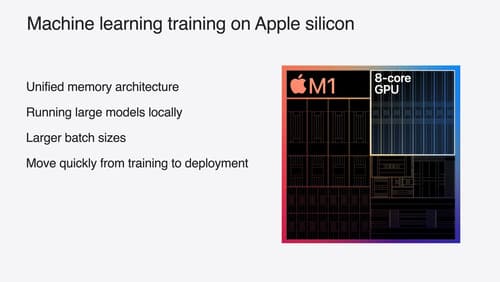
Train your machine learning and AI models on Apple GPUs
Learn how to train your models on Apple Silicon with Metal for PyTorch, JAX and TensorFlow. Take advantage of new attention operations and quantization support for improved transformer model performance on your devices.