启动优化
Asked on 2024-11-10
1 search

在WWDC 2024中,Apple介绍了多种优化技术来提升机器学习模型的性能,特别是在Apple Silicon上运行的模型。以下是一些相关的优化技术:
-
模型压缩:在“Bring your machine learning and AI models to Apple silicon”会话中,介绍了如何使用不同的压缩技术来优化模型。这包括后训练压缩和量化技术,例如将Mistio 7B模型转换为Core ML模型,并应用四位量化和状态化KV缓存技术,以提高执行速度和减少内存使用。
-
实时ML推理:在“Support real-time ML inference on the CPU”会话中,介绍了BNNS图形优化技术。这些优化包括层融合、内存共享和权重重打包,以提高模型的执行效率和内存使用效率。
-
集成和运行效率:在“Deploy machine learning and AI models on-device with Core ML”会话中,介绍了如何将模型高效地集成到应用中,并使用新的MLTensor类型来支持复杂的计算。
这些优化技术可以帮助开发者在Apple设备上更高效地运行机器学习模型,特别是在资源有限的环境中。
如果你对特定的优化技术或会话感兴趣,可以查看以下相关会话:
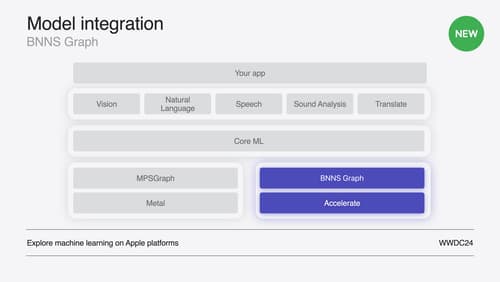
Support real-time ML inference on the CPU
Discover how you can use BNNSGraph to accelerate the execution of your machine learning model on the CPU. We will show you how to use BNNSGraph to compile and execute a machine learning model on the CPU and share how it provides real-time guarantees such as no runtime memory allocation and single-threaded running for audio or signal processing models.
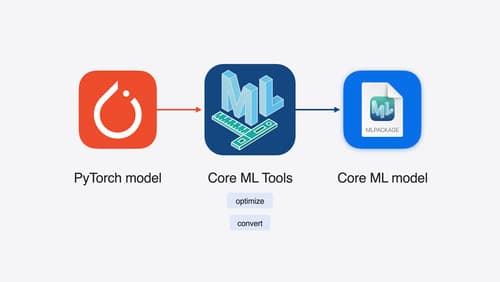
Bring your machine learning and AI models to Apple silicon
Learn how to optimize your machine learning and AI models to leverage the power of Apple silicon. Review model conversion workflows to prepare your models for on-device deployment. Understand model compression techniques that are compatible with Apple silicon, and at what stages in your model deployment workflow you can apply them. We’ll also explore the tradeoffs between storage size, latency, power usage and accuracy.
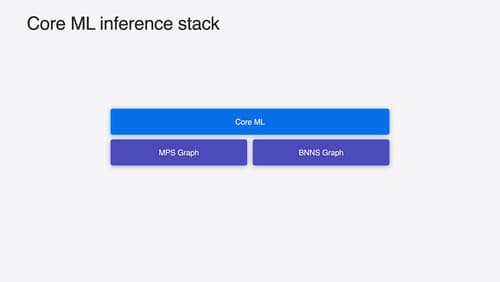
Deploy machine learning and AI models on-device with Core ML
Learn new ways to optimize speed and memory performance when you convert and run machine learning and AI models through Core ML. We’ll cover new options for model representations, performance insights, execution, and model stitching which can be used together to create compelling and private on-device experiences.