image compress
Asked on 2025-03-05
1 search

At WWDC 2024, Apple discussed various techniques for compressing machine learning models to make them suitable for deployment on devices like iPhones and iPads. In the session titled "Bring your machine learning and AI models to Apple silicon," several methods were highlighted:
-
Palletization: This technique allows for flexibility in choosing the number of bits to achieve different compression ratios. For instance, using eight-bit palletization can reduce a model's size significantly, making it more feasible for mobile devices.
-
Quantization: This involves mapping model weights to integer values, which are stored with quantization parameters to convert them back to float values when needed. This helps in reducing the model size while maintaining performance.
-
Pruning: By setting the smallest values in a weight matrix to zero, pruning helps in efficiently packing model weights with sparse representation, further reducing the model size.
-
Compression Workflows: The session also discussed workflows that use calibration data to achieve better compression results, allowing models to maintain accuracy even after significant size reduction.
For more details, you can refer to the session Bring your machine learning and AI models to Apple silicon (02:47) which covers model compression techniques.

Use HDR for dynamic image experiences in your app
Discover how to read and write HDR images and process HDR content in your app. Explore the new supported HDR image formats and advanced methods for displaying HDR images. Find out how HDR content can coexist with your user interface — and what to watch out for when adding HDR image support to your app.
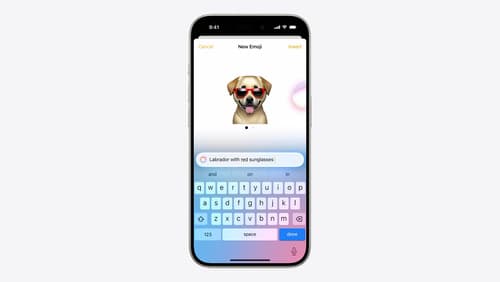
Bring expression to your app with Genmoji
Discover how to bring Genmoji to life in your app. We’ll go over how to render, store, and communicate text that includes Genmoji. If your app features a custom text engine, we’ll also cover techniques for adding support for Genmoji.
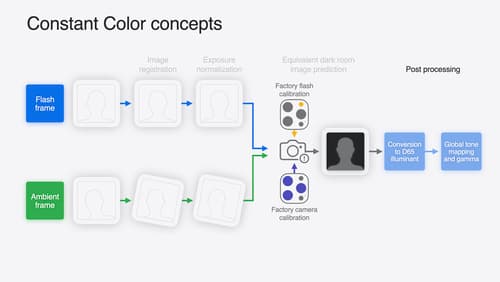
Keep colors consistent across captures
Meet the Constant Color API and find out how it can help people use your app to determine precise colors. You’ll learn how to adopt the API, explore its scientific and marketing potential, and discover best practices for making the most of the technology.