MLTensor
Asked on 2025-03-21
1 search

MLTensor is a new type introduced in Core ML that provides a convenient and efficient way to support computations typical of machine learning frameworks. It offers many common math and transformation operations and is designed to leverage Apple Silicon's powerful compute capabilities for high-performance execution. MLTensor resembles popular Python numerical libraries, making it intuitive for developers familiar with machine learning.
MLTensor is a multidimensional array defined by its shape and scalar type, where the shape specifies the length of each axis, and the scalar type indicates the type of elements it holds. It supports a broad range of operations, such as element-wise addition and multiplication, and can seamlessly work with literals. Operations are dispatched asynchronously, and tensors must be explicitly materialized to an ML-shaped array before accessing the underlying data.
For more details, you can refer to the session Deploy machine learning and AI models on-device with Core ML.
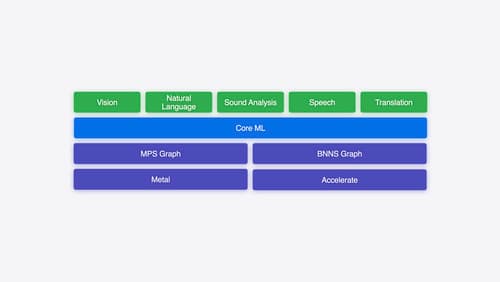
Explore machine learning on Apple platforms
Get started with an overview of machine learning frameworks on Apple platforms. Whether you’re implementing your first ML model, or an ML expert, we’ll offer guidance to help you select the right framework for your app’s needs.
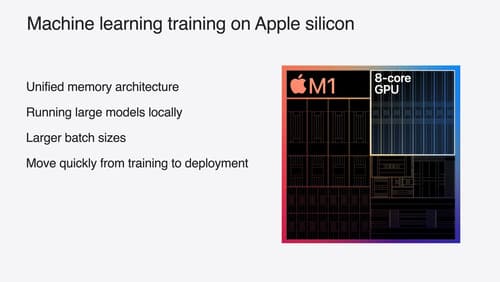
Train your machine learning and AI models on Apple GPUs
Learn how to train your models on Apple Silicon with Metal for PyTorch, JAX and TensorFlow. Take advantage of new attention operations and quantization support for improved transformer model performance on your devices.
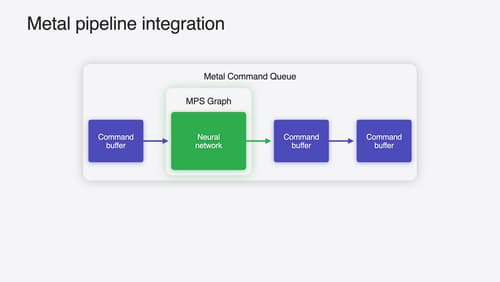
Accelerate machine learning with Metal
Learn how to accelerate your machine learning transformer models with new features in Metal Performance Shaders Graph. We’ll also cover how to improve your model’s compute bandwidth and quality, and visualize it in the all new MPSGraph viewer.