how many threads for processing matmul in Metal
Asked on 2025-03-21
1 search

The specific number of threads used for processing matrix multiplication (matmul) in Metal is not detailed in the provided context from the WWDC sessions. However, the session titled "Accelerate machine learning with Metal" discusses improvements in compute performance and optimizations for transformer models, which involve matrix multiplications. For more detailed information, you might want to explore the session Accelerate machine learning with Metal starting from the "Transformer support" chapter.
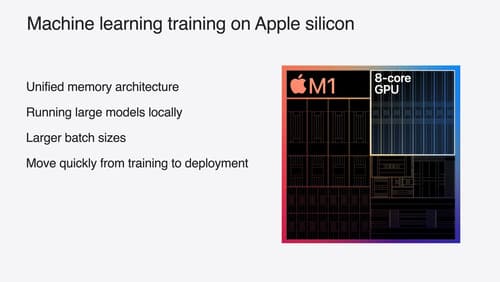
Train your machine learning and AI models on Apple GPUs
Learn how to train your models on Apple Silicon with Metal for PyTorch, JAX and TensorFlow. Take advantage of new attention operations and quantization support for improved transformer model performance on your devices.
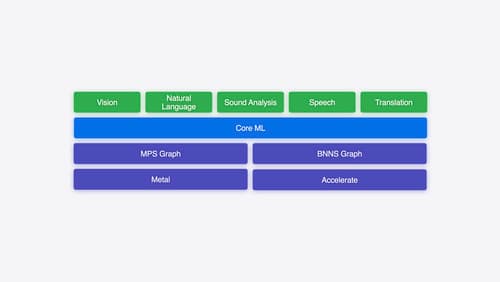
Explore machine learning on Apple platforms
Get started with an overview of machine learning frameworks on Apple platforms. Whether you’re implementing your first ML model, or an ML expert, we’ll offer guidance to help you select the right framework for your app’s needs.
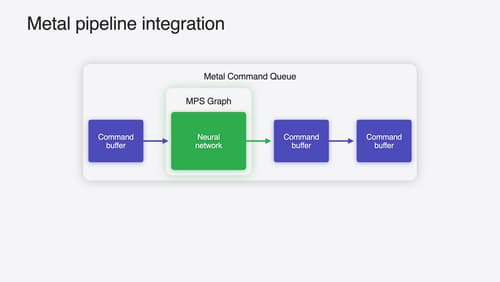
Accelerate machine learning with Metal
Learn how to accelerate your machine learning transformer models with new features in Metal Performance Shaders Graph. We’ll also cover how to improve your model’s compute bandwidth and quality, and visualize it in the all new MPSGraph viewer.