caching
Asked on 2025-04-29
1 search

Caching, particularly in the context of machine learning models, was discussed in several sessions at WWDC. A key focus was on the use of a "key-value cache" (KV cache) to improve the efficiency of transformer models, which are commonly used in large language models.
Key Points on Caching:
-
KV Cache in Transformers:
- The KV cache is used to store key and value vectors calculated at each step of the model's operation. This avoids recalculating these vectors for previous tokens, thus speeding up the decoding process.
- This technique is particularly useful for large language models to make decoding faster and more efficient.
-
Implementation in Core ML:
- In the session "Deploy machine learning and AI models on-device with Core ML," it was explained how the KV cache can be managed using Core ML states, reducing overhead and improving inference efficiency. This involves creating an empty cache to store key and value vectors, which is then updated in place.
-
Metal and Machine Learning:
- In the session "Accelerate machine learning with Metal," the use of the KV cache was also discussed. The session highlighted how to update the cache in place using operations like
sliceupdateto optimize memory usage and computation.
- In the session "Accelerate machine learning with Metal," the use of the KV cache was also discussed. The session highlighted how to update the cache in place using operations like
Relevant Sessions:
- Deploy machine learning and AI models on-device with Core ML (Models with state)
- Bring your machine learning and AI models to Apple silicon (Transformer optimization)
- Accelerate machine learning with Metal (Transformer support)
These sessions provide insights into how caching techniques can be leveraged to enhance the performance of machine learning models on Apple devices.
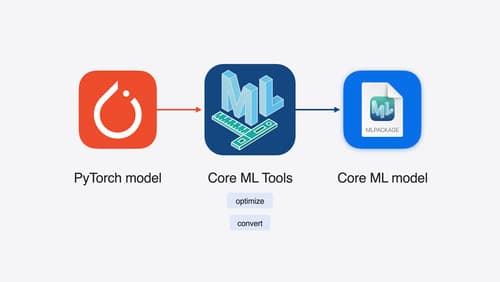
Bring your machine learning and AI models to Apple silicon
Learn how to optimize your machine learning and AI models to leverage the power of Apple silicon. Review model conversion workflows to prepare your models for on-device deployment. Understand model compression techniques that are compatible with Apple silicon, and at what stages in your model deployment workflow you can apply them. We’ll also explore the tradeoffs between storage size, latency, power usage and accuracy.
Migrate your app to Swift 6
Experience Swift 6 migration in action as we update an existing sample app. Learn how to migrate incrementally, module by module, and how the compiler helps you identify code that’s at risk of data races. Discover different techniques for ensuring clear isolation boundaries and eliminating concurrent access to shared mutable state.

Platforms State of the Union
Discover the newest advancements on Apple platforms.